4 Framing research
INCOMPLETE DRAFT
If we knew what it was we were doing, it would not be called research, would it?
―–Albert Einstein
The essential questions for this chapter are:
- What are the strategies for selecting a research area and identifying a research problem?
- How does a research problem and research aim frame the development of a research statement?
- What is a ‘research blueprint’ and how do the conceptual and practical steps involved in developing it aid the researcher as well as the scientific community?
At this point in this part of the coursebook, we have covered Data, Information, and Knowledge from the Data to Insight Hierarchy. The goal has been to provide an orientation to the main building blocks of doing text analysis. Insight is the last component of the hierarchy. However, in practical terms, it is the first step to address in an research project as goals of a research project influence all subsequent steps. In this chapter we discuss how to frame research, that is how to position your research project’s findings to contribute insight to understanding of the world. We will cover how to connect with the literature, selecting a research area and identifying a research problem, and how to design research best positioned to return relevant findings that will connect with this literature, establishing a research aim and research question. We will round out this chapter with a guide on developing a research blueprint –a working plan to organize the conceptual and practical steps to implement the research effectively and in a way that supports communicating the research findings and the process by which the findings were obtained.
Together a research area, problem, aim and question and the research blueprint that forms the conceptual and practical scaffolding of the project ensure from the outset that the project is solidly grounded in the main characteristics of good research. These characteristics, summarized by Cross (2006), are found in Table 4.1.
| Characteristic | Description |
|---|---|
| Purposive | Based on identification of an issue or problem worthy and capable of investigation |
| Inquisitive | Seeking to acquire new knowledge |
| Informed | Conducted from an awareness of previous, related research |
| Methodical | Planned and carried out in a disciplined manner |
| Communicable | Generating and reporting results which are feasible and accessible by others |
With these characteristics in mind, let’s get started with the first component to address –connecting with the literature.
4.1 Connect
4.1.1 Research area
The area of research is the first decision to make in terms of where to make a contribution to understanding. At this point, the aim is to identify a general area of interest where a researcher wants to derive insight. For those with an established research trajectory in language, the area of research to address through text analysis will likely be an extension of their prior work. For others, which include new researchers or researcher’s that want to explore new areas of language research or approach an area through a language-based lens, the choice of area may be less obvious. In either case, the choice of a research area should be guided by a desire to contribute something relevant to a theoretical, social, and/ or practical matter of personal interest. Personal relevance goes a long way to developing and carrying out purposive and inquisitive research.
So how do we get started? The first step is to reflect on your own areas of interest and knowledge, be it academic, professional, or personal. Language is at the heart of the human experience and therefore found in some fashion anywhere one seeks to find it. But it is a big world and more often than not the general question about what area to explore language use is sometimes the most difficult. To get the ball rolling, it is helpful to peruse disciplinary encyclopedias or handbooks of linguistics and language-related an academic fields (e.g. Encyclopedia of Language and Linguistics (Brown, 2005), A Practical Guide to Electronic Resources in the Humanities (Dubnjakovic & Tomlin, 2010), Routledge encyclopedia of translation technology (Chan, 2014))
A more personal, less academic, approach is to consult online forums, blogs, etc. that one already frequents or can be accessed via an online search. For example, Reddit has a wide variety of active subreddits (r/LanguageTechnology, r/Linguistics, r/corpuslinguistics, r/DigitalHumanities, etc.). Twitter and Facebook also have interesting posts on linguistics and language-related fields worth following. Through one of these social media site you may find particular people that maintain a blog worth browsing. For example, I follow Julia Silge, Rachel Tatman, and Ted Underwood, inter alia. Perusing these resources can help spark ideas and highlight the kinds of questions that interest you.
Regardless of whether your inquiry stems from academic, professional, or personal interest, try to connect these findings to academic areas of research. Academic research is highly structured and well-documented and making associations with this network will aid in subsequent steps in developing a research project.
4.1.2 Research problem
Once you’ve made a rough-cut decision about the area of research, it is now time to take a deeper dive into the subject area and jump into the literature. This is where the rich structure of disciplinary research will provide aid to traverse the vast world of academic knowledge and identify a research problem. A research problem highlights a particular topic of debate or uncertainty in existing knowledge which is worthy of study.
Surveying the relevant literature is key to ensuring that your research is informed, that is, connected to previous work. Identifying relevant research to consult can be a bit of a ‘chicken or the egg’ problem –some knowledge of the area is necessary to find relevant topics, some knowledge of the topics is necessary to narrow the area of research. Many times the only way forward is to jump in conducting searches. These can be world-accessible resources (e.g. Google Scholar) or limited-access resources that are provided through an academic institution (e.g. Linguistics and Language Behavior Abstracts), ERIC, PsycINFO, etc.). Some organizations and academic institutions provide research guides to help researcher’s access the primary literature.
Another avenue to explore are journals dedicated to areas in which linguistics and language-related research is published. In the following tables I’ve listed a number of highly visable journals in linguistics, digital humanities, and computational linguistics.
| Resource | Description |
|---|---|
| Corpora | An international, peer-reviewed journal of corpus linguistics focusing on the many and varied uses of corpora both in linguistics and beyond. |
| Corpus Linguistics and Linguistic Theory | Corpus Linguistics and Linguistic Theory (CLLT) is a peer-reviewed journal publishing high-quality original corpus-based research focusing on theoretically relevant issues in all core areas of linguistic research, or other recognized topic areas. |
| International Journal of Corpus Linguistics | The International Journal of Corpus Linguistics (IJCL) publishes original research covering methodological, applied and theoretical work in any area of corpus linguistics. |
| International Journal of Language Studies | It is a refereed international journal publishing articles and reports dealing with theoretical as well as practical issues focusing on language, communication, society and culture. |
| Journal of Child Language | A key publication in the field, Journal of Child Language publishes articles on all aspects of the scientific study of language behaviour in children, the principles which underlie it, and the theories which may account for it. |
| Journal of Linguistic Geography | The Journal of Linguistic Geography focuses on dialect geography and the spatial distribution of language relative to questions of variation and change. |
| Journal of Quantitative Linguistics | Publishes research on the quantitative characteristics of language and text in mathematical form, introducing methods of advanced scientific disciplines. |
| Resource | Description |
|---|---|
| Digital Humanities Quarterly | Digital Humanities Quarterly (DHQ), an open-access, peer-reviewed, digital journal covering all aspects of digital media in the humanities. |
| Digital Scholarship in the Humanities | DSH or Digital Scholarship in the Humanities is an international, peer reviewed journal which publishes original contributions on all aspects of digital scholarship in the Humanities including, but not limited to, the field of what is currently called the Digital Humanities. |
| Journal of Cultural Analytics | Cultural Analytics is an open-access journal dedicated to the computational study of culture. Its aim is to promote high quality scholarship that applies computational and quantitative methods to the study of cultural objects (sound, image, text), cultural processes (reading, listening, searching, sorting, hierarchizing) and cultural agents (artists, editors, producers, composers). |
| Resource | Description |
|---|---|
| Computational Linguistics | Computational Linguistics is the longest-running publication devoted exclusively to the computational and mathematical properties of language and the design and analysis of natural language processing systems. |
| LREC Conferences | The International Conference on Language Resources and Evaluation is organised by ELRA biennially with the support of institutions and organisations involved in HLT. |
| Transactions of the Association for Computational Linguistics | Transactions of the Association for Computational Linguistics (TACL) is an ACL-sponsored journal published by MIT Press that publishes papers in all areas of computational linguistics and natural language processing. |
To explore research related to text analysis it is helpful to start with the (sub)discipline name(s) you identified in when selecting your research area, more specific terms that occur to you or key terms from the literature, and terms such as ‘corpus study’ or ‘corpus-based’. The results from first searches may not turn out to be sources that end up figuring explicitly in your research, but it is important to skim these results and the publications themselves to mine information that can be useful to formulate better and more targeted searches. Relevant information for honing your searches can be found throughout an academic publication (article or book). However, pay particular attention to the abstract, in articles, and the table of contents, in books, and the cited references. Abstracts and tables of contents often include discipline-specific jargon that is commonly used in the field. In some articles there is even a short list of key terms listed below the abstract which can be extremely useful to seed better and more precise search results. The references section will contain relevant and influential research. Scan these references for publications which appear to narrowing in on topic of interest and treat it like a search in its own right.
Once your searches begin to show promising results it is time to keep track and organize these references. Whether you plan to collect thousands of references over a lifetime of academic research or your aim is centered around one project, software such as Zotero12, Mendeley, or BibDesk provide powerful, flexible, and easy-to-use tools to collect, organize, annotate, search, and export references. Citation management software is indispensable for modern research –and often free!
As your list of relevant references grows, you will want to start the investigation process in earnest. Begin skimming (not reading) the contents of each of these publications, starting with the most relevant first13. Annotate these publications using highlighting features of the citation management software to identify: (1) the stated goal(s) of the research, (2) the data source(s) used, (3) the information drawn from the data source(s), (4) the analysis approach employed, and (5) the main finding(s) of the research as they pertain to the stated goal(s). Next, in your own words, summarize these five key areas in prose adding your summary to the notes feature of the citation management software. This process will allow you to efficiently gather and document references with the relevant information to guide the identification of a research problem, to guide the formation of your problem statement, and ultimately, to support the literature review that will figure in your project write-up.
From your preliminary annotated summaries you will undoubtedly start to recognize overlapping and contrasting aspects in the research literature. These aspects may be topical, theoretical, methodological, or appear along other lines. Note these aspects and continue to conduct more refine searches, annotate new references, and monitor for any emerging patterns of uncertainty or debate (gaps) which align with your research interest(s). When a promising pattern takes shape, it is time to engage with a more detailed reading of those references which appear most relevant highlighting the potential gap(s) in the literature. At this point you can focus energy on more nuanced aspects of a particular gap in the literature with the goal to formulate a problem statement. A problem statement directly acknowledges a gap in the literature and puts a finer point on the nature and relevance of this gap for understanding. This statement reflects your first deliberate attempt to establish a line of inquiry. It will be a targeted, but still somewhat general, statement framing the gap in the literature that will guide subsequent research design decisions.
4.2 Findings
4.2.1 Research aim
With a problem statement in hand, it is now time to consider the goal(s) of the research. A research aim frames the type of inquiry to be conducted. Will the research aim to explain, evaluate, or explore? In other words, will the research seek to test a particular relationship, assess the potential strength of a particular relationship, or uncover novel relationships? As you can appreciate, the research aim is directly related to the analysis methods we touched upon in Chapter 3.
To gauge how to frame your research aim, reflect on the literature that led you to your problem statement and the nature of the problem statement itself. If the gap at the center of the problem statement is a lack of knowledge, your research aim may be exploratory. If the gap concerns a conjecture about a relationship, then your research may take a predictive approach. When the gap points to the validation of a relationship, then your research will likely be inferential in nature. Before selecting your research aim it is also helpful to consult the research aims of the primary literature that led you to your research statement. Consider how your research statement relates the previous literature. Do you aim to test a hypothesis based on previous exploratory analyses? Are you looking to generate new knowledge in an (apparently) uncharted area?
In general, a problem statement which addresses a smaller, nuanced gap will tend to adopt similar research aims as the previous literature while a larger, more divergent gap will tend to adopt a distinct research aim. This is not a hard rule, but more of a heuristic, however, and it is important to be familiar with both the previous literature, the nature of different types of analysis, and the goals of the research to ensure that the research is best-positioned to generate findings that will contribute to the existing body of understanding in a principled way.
4.2.2 Research question
The next step in research design is to craft the research question. A research question is clearly defined statement which identifies an aspect of uncertainty and the particular relationships that this uncertainty concerns. The research question extends and narrows the line of inquiry established in the research statement and research aim. The research statement can be seen as the content and the research aim as the form.
The form of a research question will vary based on the analysis approach. For inferential-based research, the research question will actually be a statement, not a question. This statement makes a testable claim about the nature of a particular relationship –i.e. asserts a hypothesis. For illustration, let’s return to one of the hypotheses we previously sketched out in Chapter 3, leaving aside the implicit null hypothesis.
Women use more questions than men in spontaneous conversations.
For predictive- and exploratory-based research, the research question is in fact a question. A reframing of the example hypothesis for a predictive-based research question might looks something like this.
Can the number of questions used in spontaneous conversations predict if a speaker is male or female?
And a similar exploratory-based research question would take this form.
Do men and women differ in terms of the number of questions they use in spontaneous conversations?
The central research interest behind these hypothetical research questions is, admittedly, quite basic. But from these simplified examples, we are able to appreciate the similarities and differences between the forms of research statements that correspond to distinct research aims.
In terms of content, the research question will make reference to two key components. First, is the unit of analysis. The unit of analysis is the entity which the research aims to investigate. For our three example research aims, the unit of analysis is the same, namely men and women. Note, however, that the current unit of analysis is somewhat vague in the example research questions. A more precise unit of analysis would include more information about the population from which the men and women are drawn (e.g English speakers, American English speakers, American English speakers of the Southeast, etc.).
The second key component is the unit of observation. The unit of observation is the primary element on which the insight into the unit of analysis is derived and in this way constitutes the essential organization unit of the data to be collected. In our examples, the unit of observation, again, is unchanged and is spontaneous conversations. Note that while the unit of observation is key to identify as it forms the organizational backbone of the research, it is very common for the research to derive variables from this unit to provide evidence to investigate the research question. In the previous examples, we identified the number of conversations as part of the research question. But in other cases a researcher may seek to understand other aspects of questions in spontaneous conversations (i.e type of question, features of questions, etc.). The unit of observation, however, would remain the same.
4.3 Blueprint
Efforts to craft a research question are a very important aspect of developing purposive, inquisitive, and informed research (returning to Cross’s characteristics of research). Moving beyond the research question in the project means developing and laying out the research design in a way such that the research is Methodical and Communicable. In this coursebook, the method to achieve these goals is through the development of a research blueprint. The blueprint includes two components: (1) the process of identifying the data, information, and methods to be used and (2) the creation of a plan to structure and document the project.
As Ignatow & Mihalcea (2017) point out:
Research design is essentially concerned with the basic architecture of research projects, with designing projects as systems that allow theory, data, and research methods to interface in such a way as to maximize a project’s ability to achieve its goals …. Research design involves a sequence of decisions that have to be taken in a project’s early stages, when one oversight or poor decision can lead to results that are ultimately trivial or untrustworthy. Thus, it is critically important to think carefully and systematically about research design before committing time and resources to acquiring texts or mastering software packages or programming languages for your text mining project.
4.3.1 Identify
Importance of identifying and documenting the key aspects required to conduct the research cannot be understated. On the one hand this process links concept to implementation. In doing so, a researcher is better-positioned to conduct research with a clear view of what will be entailed. On the other hand, a promising research question, on paper, may present challenges that may require modification or reevaluation of the viability of the project. It is not uncommon to encounter roadblocks or even dead-ends for moving a well-founded research question forward when considering the available data, a researcher’s (current) technical and/ or research skills, and the given time frame for the project. In practice, the process of identifying the data, information, and methods of analysis are considered in tandem with the investigative work to develop a research aim and research question. In this subsection I will cover the main characteristics to consider when developing a research blueprint.
The first, and most important, part of establishing a research blueprint is to identify a viable data source. Regardless of how you find and access the data, it is essential to vet the corpus sample in light of the research question. In the case that research is inferential in nature, the sampling frame of the corpus is of primary importance as the goal is to generalize the findings to a target population. A corpus resource should align, to the extent feasible, with this target population. For predictive and exploratory research, the goal to generalize a claim is not central and for this reason the there is some freedom in terms of how representative a corpus sample is of a target population. Ideally a researcher will find and be able to model a language population of target interest. Since the goal, however, is not to test a hypothesis, but rather to explore particular or potential relationships, either in an predictive or exploratory fashion, the research can often continue with the stipulation that the results are interpreted in the light of the characteristic of the available corpus sample.
The second step is to identify the key variables need to conduct the research are and then ensure that this information can be derived from the corpus data. The research question will reference the unit of analysis and the unit of observation, but it is important at this point to then pinpoint what the key variables will be. If the unit of observation is spontaneous conversations. The question as to what aspects of these conversations will be used in the analysis. In the research questions presented in this chapter, we will want to envision what needs to be done to generate a variable which measures the number of questions in each of the conversations. In other research, their may be features that need to be extracted and recoded to address the research question. Other variables of importance may be non-linguistic in nature. Provided the corpus has the required meta-data for the research, variables can be normalized, recoded, and generated from the corpus itself to fit research needs. In cases where there the meta-data is incomplete for the goals of the research, it is sometimes possible to merge meta-data from other sources.
The third step is to identify a method of analysis. The selection of the analysis approach that was part of the research aim and then the research question goes a long way to narrowing the methods that a researcher must consider. But there are a number of factors which will make some methods more appropriate than others. In inferential research, the number and information values of the variables to be analyzed will be of key importance (Gries, 2013). The informational value of the dependent variable will again narrow the search for the appropriate method. The number of independent variables also plays an important role. For example, a study with a categorical dependent variable with a single categorical independent variable will lead the researcher to the Chi-squared test. A study with a continuous dependent variable with multiple independent variables will lead to linear regression. Another aspect of note for inference studies is the consideration of the distribution of continuous variables –a normal distribution will use a parametric test where a non-normal distribution will use a non-parametric test. These details need not be nailed down at this point, but it is helpful to have them on your radar to ensure that when the time comes to analyze the data, the appropriate steps are taken to test for normality and then apply the correct test.
For predictive-based research, the informational value of the target variable is key to deciding whether the prediction will be a classification task or a numeric prediction task. This has downstream effects when it comes time to evaluate and interpret the results. Although the feature engineering process in predictive analyses means that the features do not need to be specified from the outset and can be tweaked and changed as needed during an analysis, it is a good idea to start with a basic sense of what features most likely will be helpful in developing a robust predictive model. Furthermore, while the number and informational values of the features (predictor variables) are not as important to selecting a prediction method (algorithm) as they are in inferential analysis methods, it is important to recognize that algorithms have strengths and shortcomings when working large numbers and/ or types of features (Lantz, 2013).
Exploratory research is the least restricted of the three types of analysis approaches. Although it may be the case that a research will not be able to specify from the outset of a project what the exact analysis methods will be, an attempt to consider what types of analysis methods will be most promising to provide results to address the research question goes a long way to steering a project in the right direction and grounding the research. As with the other analysis approaches, it is important to be aware of what the analysis methods available and what type of information they produce in light of the research question.
In sum, the identification of the data, information, and analysis methods that will be used in the proposed research are key to ensuring the research is viable. Be sure to document this process in prose and describe the strengths and potential shortcomings of (1) the corpus data selected, (2) the information to be extracted for analysis, and (3) the analysis method(s) that are appropriate for the research aim and what the evaluation method will be. Furthermore, not every eventuality can be foreseen. It is helpful to include a description of aspects of this process which may pose challenges and to include potential contingency plans as part of this prose description.
4.3.2 Plan
The next step in creating a research blueprint is to consider how to physically implement your project. This includes how to organize files and directories in a fashion that both provides the researcher a logical and predictable structure to work with but also ensures that the research is Communicable. On the one hand, communicable research includes a strong write-up of the research, but, on the other hand, it is also important that the research is reproducible. Reproducibility strategies are a benefit to the researcher (in the moment and in the future) as it leads to better work habits and to better teamwork and it makes changes to the project easier. Reproducibility is also of benefit to the scientific community as shared reproducible research enhances replicability and encourages cumulative knowledge development (Gandrud, 2015).
There are a set of guiding principles to accomplish these goals (Gentleman & Temple Lang, 2007; Marwick, Boettiger, & Mullen, 2018).
- All files should be plain text which means they contain no formatting information other than whitespace.
- There should be a clear separation between the data, method, and output of research. This should be apparent from the directory structure.
- A separation between original data and derived data should be made. Original data should be treated as ‘read-only’. Any changes to the original data should be justified, generated by the code, and documented (see point 6).
- Each analysis file (script) should represent a particular, well-defined step in the research process.
- Each analysis script should be modular –that is, each file should correspond to a specific goal in the analysis procedure with input and output only corresponding to this step.
- All analysis scripts should be tied together by a ‘master’ script that is used to coordinate the execution of all the analysis steps.
- Everything should be documented. This includes analysis steps, script code comments, data description in data dictionaries, information about the computing environment and packages used to conduct the analysis, and detailed instructions on how to reproduce the research.
These seven principles can be physically implemented in countless ways. In recent years, there has been a growing number of efforts to create R packages and templates to quickly generate the scaffolding and tools to facilitate reproducible research. Some notable R packages include workflowr and ProjectTemplate but there are many other resources for R included on the CRAN Task View for Reproducible Research. There are many advantages to working with pre-existing frameworks for the savvy R programmer.
In this coursebook, however, I have developed a project template (available on GitHub) which I believe simplifies and makes the process more transparent for beginning and intermediate R programmers, the directory structure is provided below.
#> ../project_template/
#> ├── README.md
#> ├── _pipeline.R
#> ├── analysis
#> │ ├── 1_acquire_data.Rmd
#> │ ├── 2_curate_dataset.Rmd
#> │ ├── 3_transform_dataset.Rmd
#> │ ├── 4_analyze_dataset.Rmd
#> │ ├── 5_generate_article.Rmd
#> │ ├── _session-info.Rmd
#> │ ├── _site.yml
#> │ ├── index.Rmd
#> │ └── references.bib
#> ├── data
#> │ ├── derived
#> │ └── original
#> └── output
#> ├── figures
#> └── resultsLet me now describe how this template structure aligns with the seven principles of quality reproducible research.
- All files are plain text (e.g.
.R,.Rmd,.csv,.txt, etc.). - There are three main directories
analysis/,data/, andouput/. - The
data/directory contains sub-directories fororiginal(‘read-only’) data andderiveddata. - The
analysis/directory contains five scripts which are numbered to correspond with their sequential role in the research process. - Each of these analysis scripts are designed to be modular; input and output must be explicit and no intermediate objects are carried over to other analysis scripts. Dataset output should be written to and read from the
data/derived/directory. Figures and statistical results should be written to and read fromoutput/figures/andoutput/resultsrespectively. - All of the analysis scripts, and therefore the entire project, are tied to the
_pipeline.Rscript. To reproduce the entire project only this script need be run. - Documentation takes place at many levels. The
README.mdfile is the first file that a researcher will consult. It contains a brief description of the project goals and how to reproduce the analysis. Analysis scripts use the Rmarkdown format (.Rmd). This format allows researchers to interleave prose description and executable code in the same script. This ensures that the rationale for the steps taken are described in prose, the code is made available to consult, and that code comments can be added to every line. The_sesssion-info.Rmdscript is merged with each analysis script to provide information about the computing environment and packages used to conduct each step analysis. As this is a template, no data or datasets appear. However, once data is acquired and that data is curated and transformed, documentation for these resources should be documented for each resource in a data dictionary along side the data(set) itself.
The aspects of the project template described in points 1-7 together form the backbone for reproducible research. This template, however, includes additional functionality to enhance efficient and communicable research. The _pipeline.R script executes the analysis scripts in the analysis directory, but as a side effect also produces a working website and a journal-ready article for publishing your analysis, results, and findings to the web in HTML and PDF format. The index.Rmd file is the splash page for the website and is a good place to house your pre-analysis investigative work including your research area, problem, aim, and question and to document your research blueprint including the identification of viable data resource(s), the key variables for the analysis, the analysis method, and the method of assessment. All Rmarkdown files provide functionality for citing and organizing references. The references.bib file is where references are stored and can be used to include citations that support your research throughout your project.
4.3.3 Prepare
This template will allow you to organize your research design and align it with implementation steps to conduct quality reproducible research. To prepare for your analysis, you will need to download or fork and clone this template from the GitHub repository and then make some adjustments to personalize this template for your research.
To create a local copy of this project template either:
- Download and decompress the .zip file
- If you have git installed on your machine and a GitHub account, fork the repository to your own GitHub account. Then open a terminal in the desired location and clone the repository. If you are using RStudio, you can setup a new RStudio Project with the clone using the ‘New Project…’ dialog, choosing ‘Version Control’, and following the steps.
Before you begin configuring and adding your project-specific details to this template. Reproduce this project ‘as-is’ to confirm that it builds on your local machine.
In RStudio or in R session in a Terminal application, open the console in the root directory of the project. Then run:
source("_pipeline.R")It will take some time to complete, when it does the prompt (>) in the console will return. Then navigate to and open docs/index.html in a browser.
Once you have confirmed that the project template builds, then you can begin to configure the template to reflect your project. There a few files to consider first. These files are places where the title of your project should appear.
README.md_pipeline.Ranalysis/index.Rmd
After updating these files, build the project again and make sure that the new changes appear as you would like them. You are now ready to start your research project!
Summary
The aim of this chapter is to provide the key conceptual and practical points to guide the development of a viable research project. Good research is purposive, inquisitive, informed, methodological, and communicable. It is not, however, always a linear process. Exploring your area(s) of interest and connecting with existing work will help couch and refine your research. But practical considerations, such as the existence of viable data, technical skills, and/ or time constrains, sometimes pose challenges and require a researcher to rethink and/ or redirect the research in sometimes small and other times more significant ways. The process of formulating a research question and developing a viable research plan is key to supporting viable, successful, and insightful research. To ensure that the effort to derive insight from data is of most value to the researcher and the research community, the research should strive to be methodological and communicable adopting best practices for reproducible research.
This chapter concludes the Orientation section of this coursebook. At this point the fundamental characteristics of research are in place to move a project towards implementation. The next section, Preparation, aims to cover the acquisition, curation, and transformation of data in preparation for analysis. These are the first steps in putting a research blueprint into action and by no coincidence the first components in the Data to Insight Hierarchy. Following the Preparation section our attention will turn to the implementation of the three analysis approaches we have covered: inference, prediction, and exploration. Throughout these next sections we will maintain our aim to develop methodological and communicable research by connecting our implementation process to reproducible programming strategies.
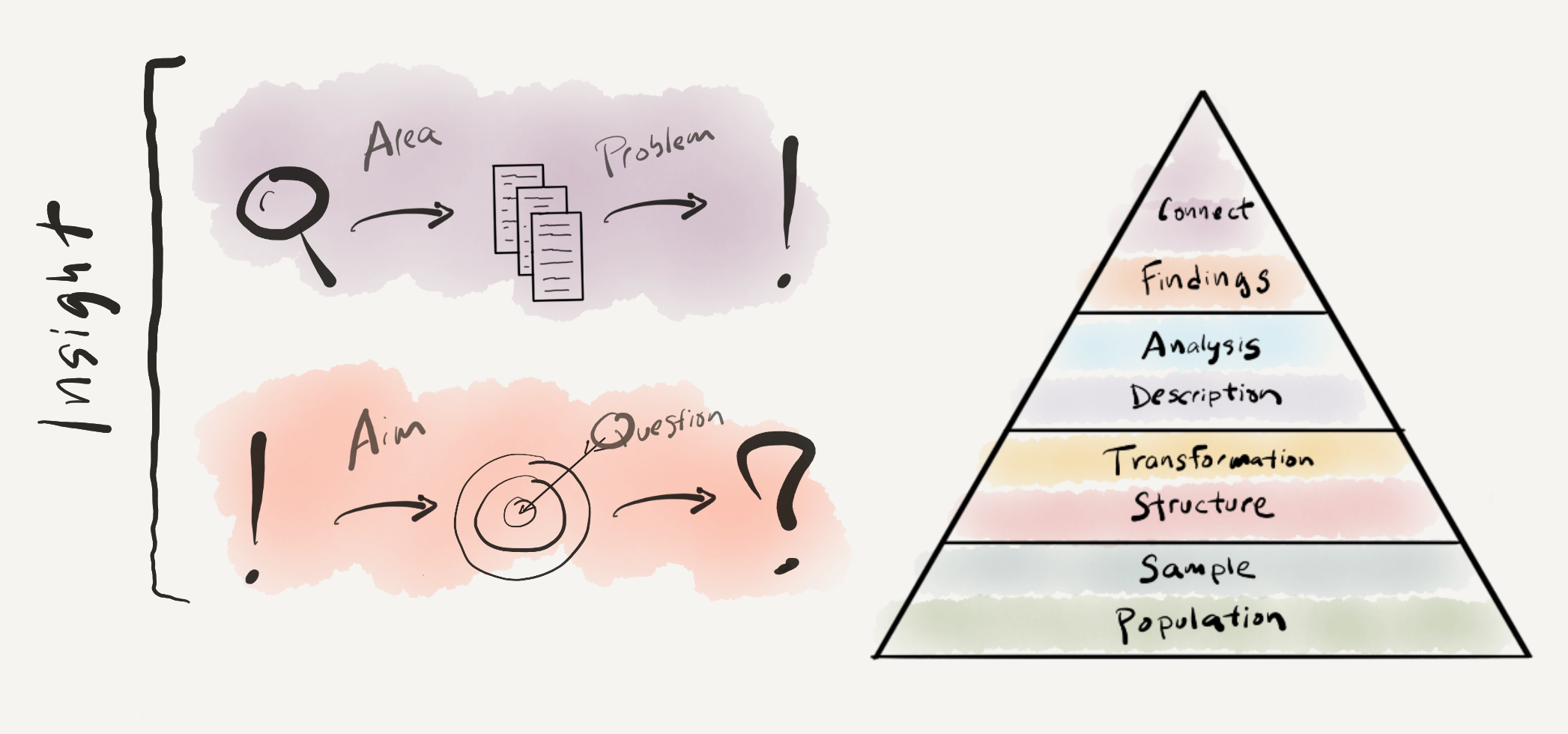
Figure 4.1: Framing research: visual summary